

A patent recently uncovered from AMD describes an intricate GPU structure based on chiplets, offering customizable pipelines. Current GPUs come with a fixed datapath that utilizes different hardware elements for processing various types of data. The GPU outlined in the patent introduces three distinct arrangement modes tailored for different workloads. The image below provides a visual representation of the proposed GPU:
The design features three shader clusters, each comprising three shader engine dies and a front-end scheduler die. Each cluster can function as an independent GPU capable of processing its allocated tasks. The Navi 31 GPU that powers the Radeon RX 7900 XTX consists of six shader engines, each equipped with 8 CUs or 512 cores. The three different modes mentioned in the patent alter the scheduler or command processor of the shader clusters.
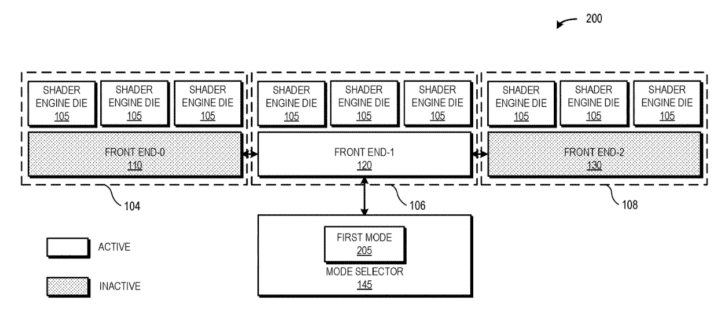
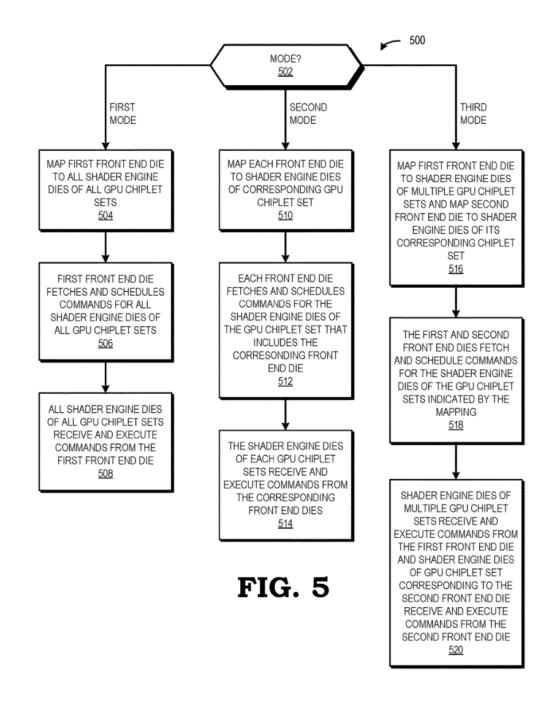
The first mode involves a single front-end die managing all three shader clusters and handling the task fetching, dispatch, and scheduling for the entire multi-chip module (MCM) GPU. This setup represents a basic configuration of such a device with a sole front-end die and multiple shader engine dies. However, potential drawbacks include latency issues and elevated bandwidth demands for communication with distant shader dies, which can be mitigated through a faster interconnect and an incorporated high-speed cache.
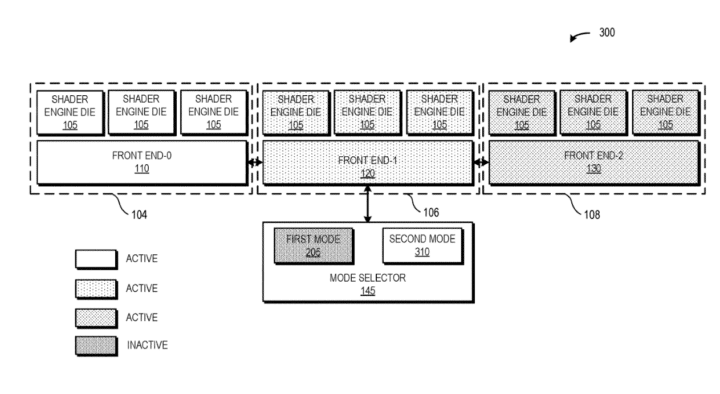
The second mode adopts a more parallel approach. Each shader cluster is overseen by its corresponding front-end unit, splitting the scheduling tasks evenly among the three clusters. This strategy aims to maximize utilization, although effective coordination between the clusters is essential depending on the method of task allocation. A comparable setup is expected in the upcoming Radeon RX 9900 XTX or any GPU utilizing multiple shader dies.
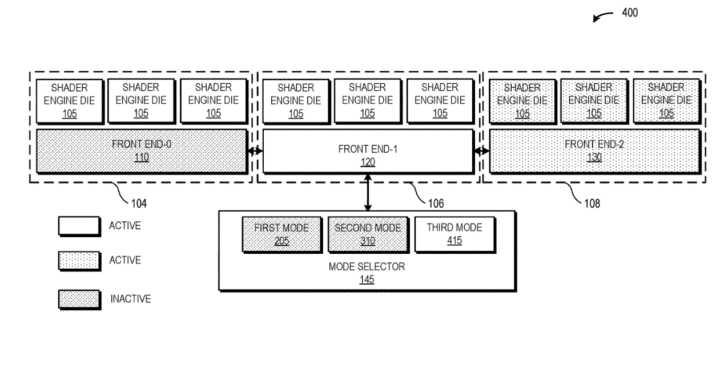
The third mode combines elements from the first two modes. In this scenario, the central front end coordinates the task scheduling for its designated shader cluster and one of the other two clusters, while the third cluster is managed by its respective front end. This pipeline configuration is likely efficient for workloads that are not frontend-constrained and often result in idle schedulers.
The notion of employing distinct datapaths or pipelines for different workloads presents an intriguing concept that chip manufacturers will undoubtedly explore further. However, for gaming GPUs, simplicity is key. Excessive inter-chip data transfers lead to significant latency penalties and increased power consumption. Therefore, it is unlikely that the Radeon RX 9900 XTX (RDNA 5 flagship) will feature more than two compute dies.
For additional insights, visit:
For the source article, check out: AMD Chiplet GPU with Customizable Pipelines: Radeon RX 9900 XTX








