

AMD disclosed its Ryzen AI 300 “Strix Point” processors in conjunction with the Ryzen 9000 desktop lineup at Computex earlier in the month. The latter will be the initial hybrid core design from Team Red (apart from Phoenix 2), anticipated to debut this autumn. Apart from the fundamental specifications and internal benchmarks, AMD hasn’t revealed a lot about these processors.
Specifications of AMD Ryzen AI 300
The Ryzen AI HX 370 will present 12 CPU cores and 24 threads (from Zen 5) with a maximum boost clock of 5.1 GHz. It features 36 MB of L3 cache and a Radeon 890M GPU containing 16 CUs (1024 shaders) running at 2.9 GHz. The TDP of this model stands at 28W, adjustable to 54W or 15W.
The Ryzen AI 365 decreases the number of cores to 10 (equivalent to 20 threads) clocked at a top boost clock speed of 5 GHz along with 34 MB of L3 cache. It integrates the Radeon 880M iGPU with 12 CUs (768 shaders) at a maximum core clock of 2.9 GHz. Both variants include a 50 TOP NPU powered by the XDNA 3 architecture.
Initial evaluations conducted by David Huang have shown minimized Zen 5 “P-cores” and low-power Zen 5c “E-cores” with a peak boost clock of 4 GHz. The only processor tested was the Ryzen AI 9 365, which incorporates 4x Zen 5 “P-cores” and 6x Zen 5c “E-cores” on a unified die separated into two CCXs (CCD vs CCX explained).
Ryzen AI 9 365: Strix Point “Zen 5” Instruction Throughput
In line with earlier Ryzen mobile APUs, the Zen 5 CCX contains 16 MB of L3 cache (in comparison to 32 MB on desktop and Epyc) and a reduced boost clock. AMD has also halved the SIMD throughput (execution backend) with a decreased L1 load bandwidth. The Zen 5c CCX comprises 8 MB of L3 cache with the same ISA as Zen 5, but capped at 4 GHz.

The Zen 5 core on Strix Point showcases notable throughput enhancements in specific instructions, but mainly delivers similar performance to Zen 4 due to reduced execution bandwidth. The store bandwidth is enhanced with 128-bit and 256-bit instructions, while the load throughput remains unaltered.
The branch prediction has received substantial improvements with broader BTBs, raising the non-taken branches from 2 to 3, and taken-branches from 1 to 2. However, the integer addition (128/256-bit) throughput is half of Zen 4 (presumably due to the sleeker execution units). All SSE/AVX/AVX512 additions also necessitate 2 cycles, versus a single cycle on Zen 4.
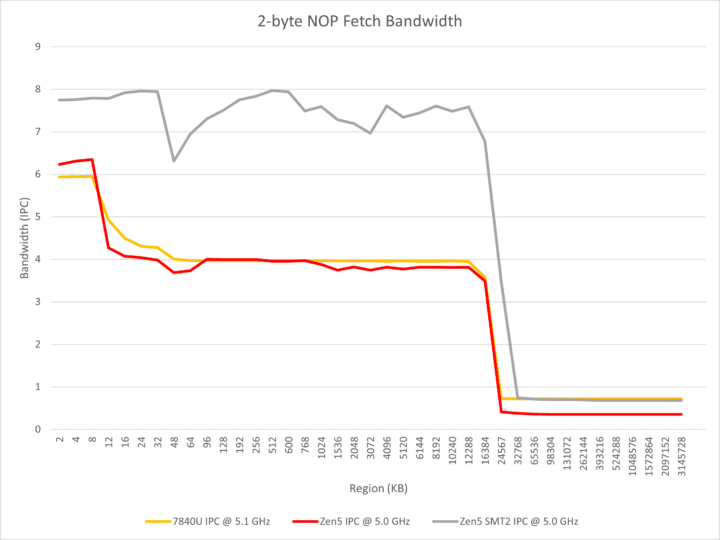
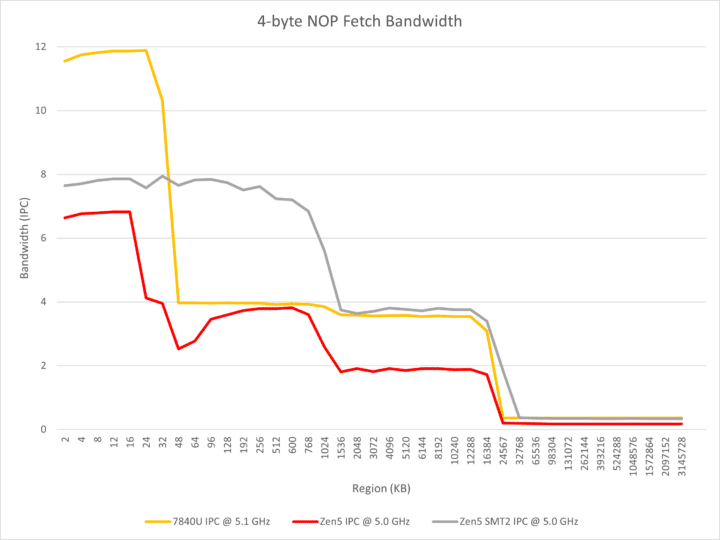
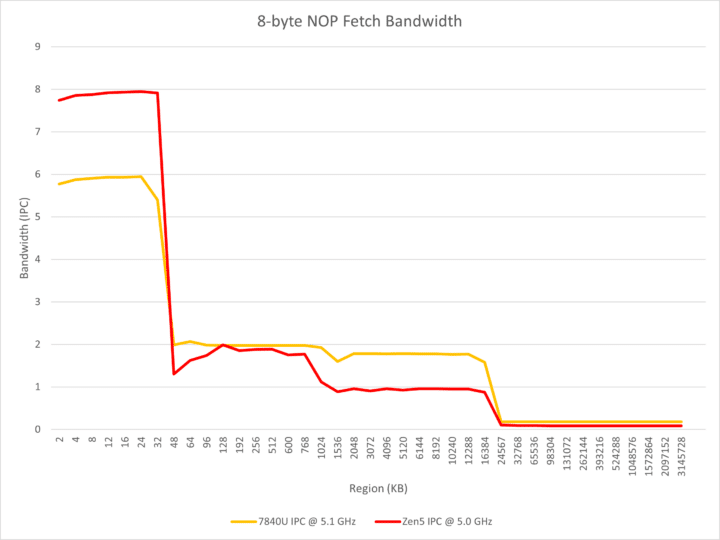
AMD Zen 5 Dual Front-end: 8-wide Decoder?
The front-end is, by far, the most captivating element of Zen 5. The Ryzen AI 9 365 cores are equipped with a dual front-end, similar to Bulldozer and Intel’s Crestmont/Tremont E-cores. It comprises 2x 4-wide decoders capable of operating independently. Each decoder can fetch instructions from two sources, facilitating two taken-branches per cycle. In SMT2 mode, one thread can utilize one decoder each, augmenting the throughput to 8.
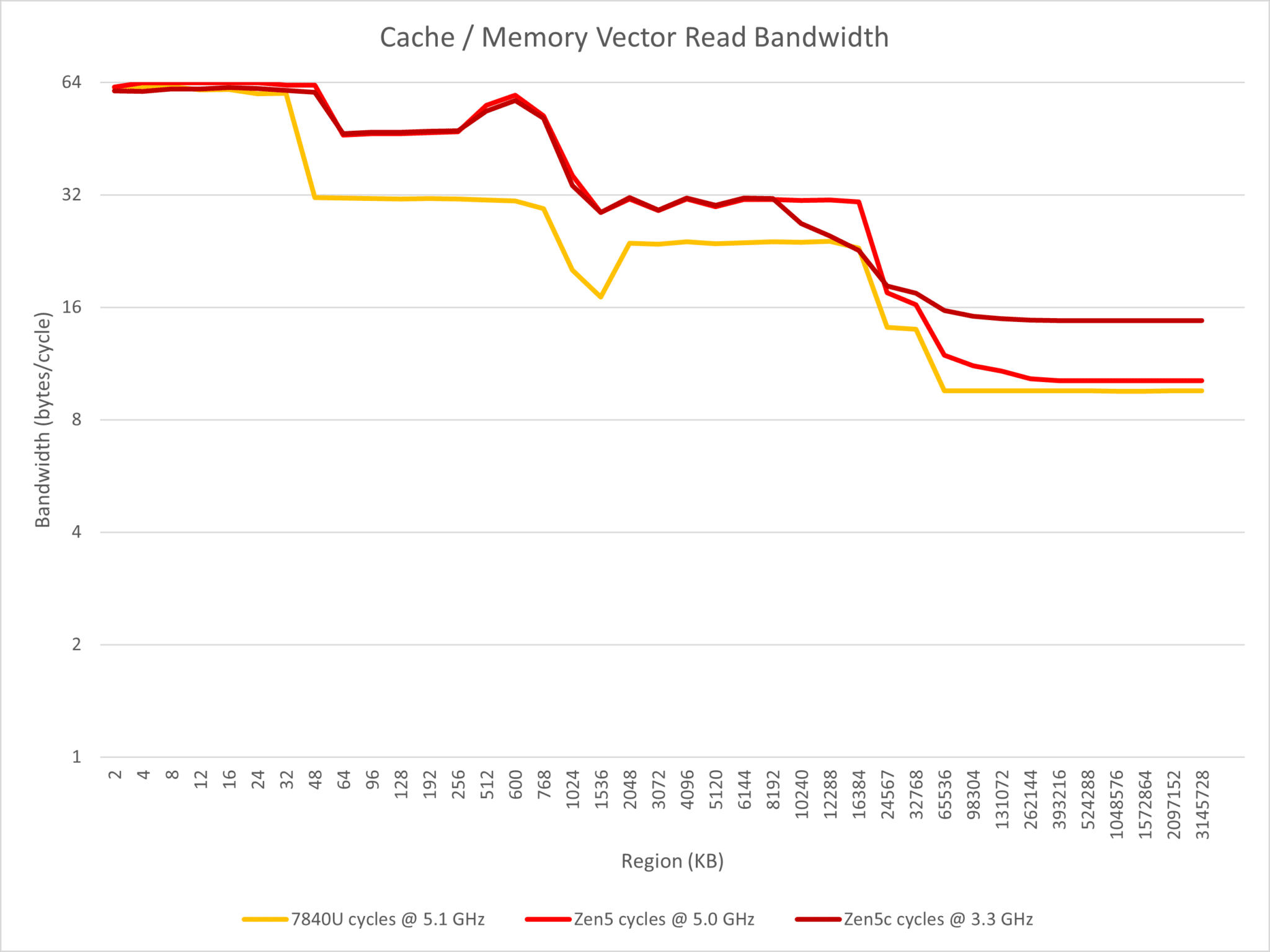
Conversely, Zen 5 is constrained to 4-wide decoding when handling consecutive NOP instructions on the same thread. It also seems to employ a smaller op-cache of 4K entries versus 6.75K on Zen 4. While the L1 to L2 and L1 to FP bandwidths are doubled, the DRAM to L3 bandwidth is decreased by 50%. Nonetheless, the single-threaded L3 read bandwidth is 32 bytes per cycle, up from 24 bytes on Zen 4, with the latency slashed from 50 cycles to 46 cycles on Zen 5.
Despite utilizing the enhanced ladder L3 interconnect, the core-to-core latency on Strix Point mirrors that of Phoenix and Hawk Point. This might alter on desktop CPUs based on the FCLK and MCLK.
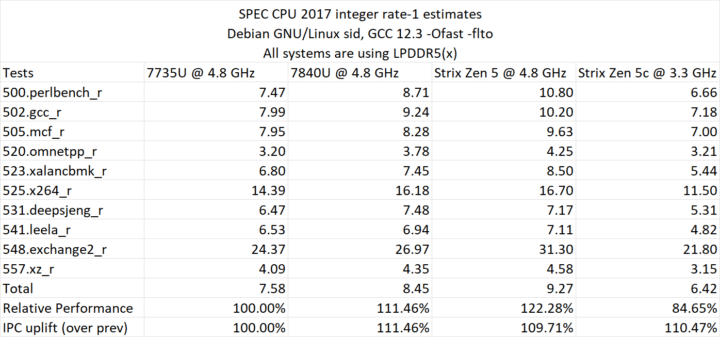
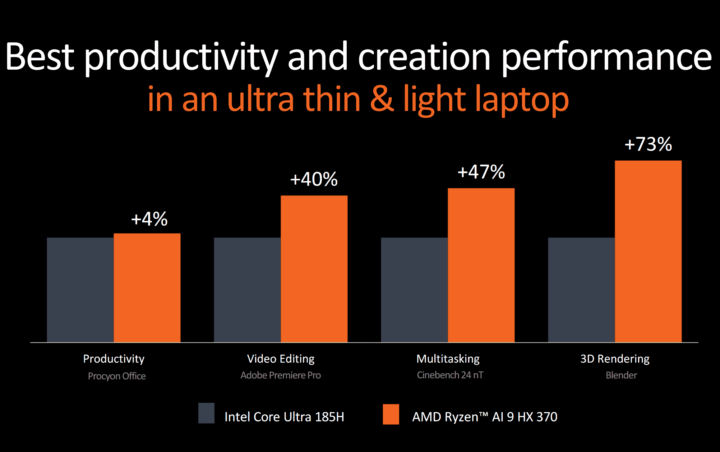
In the SPEC CPU benchmark, Zen 5 exhibits an average IPC progression of around ~10% over Zen 4 with all cores clocked at 4.8 GHz. Geekbench 5 and 6 demonstrate a 15-17% enhancement in IPC, although neither provides a precise representation of extended compute-intensive or content-creation workloads. Overall, Strix Point emerges as a respectable improvement over Phoenix/Hawk Point, yet the reductions to the SIMD units may lead to increased costs.
Access full article and images at: AMD Ryzen AI 300 Strix Point Cores Article








